Artificial Intelligence (AI) is an umbrella term for systems with (seemingly) cognitive abilities. Machine Learning techniques, as a subset of AI systems, have proven great advances, even surpassing human expert panels in some cases. The advent of computing power has enabled deep neural networks but are older techniques still viable? Is your case suited for the next system to surpass human expert level and what should be taken into account when choosing a Machine Learning technique ? Time to take stock of this ever expanding field.
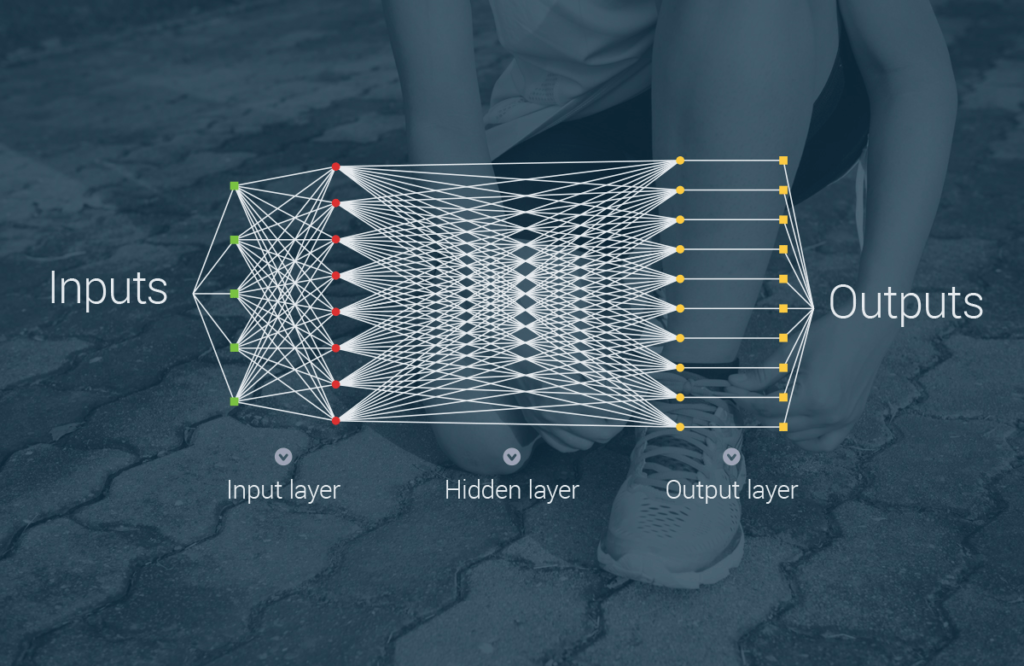
Although there is future hope for more generalist AI systems, the application of supervised Machine Learning has been one of the more fruitful enterprises within the field of AI. The application of deep neural networks have proven especially successful for specialist systems in healthcare & medicine. In some cases they even surpassed human specialists. This has been proven in many cases: Enletic is a start-up where 1.000 examples were used to build an algorithm that was more accurate at diagnosing lung cancer than a panel of 4 expert radiologists1, Deep Learning can classify skin cancer with dermatologist-level accuracy2, or the case where researchers developed an algorithm which exceeds the performance of board certified cardiologists in detecting a wide range of heart arrhythmia from electrocardiograms recorded with a single-lead wearable monitor3.
This article helps you to translate new artificial intelligence possibilities into new or improved products in your specific healthcare expertise. Furthermore, you will have a more thorough understanding of Deep Learning versus other types of Machine Learning techniques.
1. What output are you looking for?
What output would you like the system to provide you with? This might impact the selection of your model and the amount of data needed for training.
The output can be answers to questions, automated actions, predictions, diagnoses, classifications, decision support and many more.
2. On which input will the output be based?
What information might help you get the answer you need and what can help to enrich it? Think of what data you want first, worry about digitizing it later.
Some top of mind examples:
- Images (3D or 2D)
- Time series data
- Weight
- Vital signs (ECG, EEG, PPG, SpOx, HR, blood pressure, blood gas analysis …)
- Health record data
- Speech fragments
- Written text fragments
You can add any parameter with a suspected correlation with the intended output parameter. This type of research is often way ahead of practices being used in daily medical practice. You can add them and dump them when you discover they don’t add enough value.
3. Can you access the data?
Knowing that you need a certain input is not the same as getting your hands on it. In this step you try to identify what it takes to get the data. You might be able to re-use existing datasets or you might have to capture your own.
If the data is in hospital databases all over the world, you will have to find a way to access it. Merely asking might not be enough. Data privacy laws might prevent datasets being shared or healthcare professionals might think sharing their data is risky. You might uncover treatment mistakes. Even worse, they might be helping you to render some of their skills obsolete. Kind of like using Internet Explorer to download Google Chrome.
Make sure to check the availability of online databases first, they are a valuable asset. In a recent project we needed to estimate the absolute blood pressure based on ppg data. We used the MIMIC III database that is openly available. Although not a perfect fit for the project, it allowed us to start prototyping fast and use transfer learning techniques to solve the problem.
We use the following online datasets:
4. How can you gather data if it’s not available (yet)?
When there are no suitable datasets available you have to create your own. This can be a daunting task because the capture of data often requires new hardware or software and has to be incorporated into the workflow of healthcare professionals. Limiting interference with the workflow is paramount.
In our recent blood pressure estimation project we set up a clinical test to gather validation data.
These are the steps we took:
- Use knowledge about desired outputs to determine the requirements for a controlled experiment (amount of samples measured, conditions of the measurements …). It helps to look at previous studies on related topics to determine the conditions and specifications of the clinical tests.
- Find a medical team that is interested in the cooperation. Try to work out a mutually beneficial study that maximizes the buy-in from the medical team.
- Create a test protocol together.
- Select or create solutions to integrate the data capturing in the workflow without disturbing the day-to-day operations. You might want to consider creating tools that have added value for the medical team or patient outside of the data capturing.
- Getting approval from the ethical committee based on the protocol. This step is not to be underestimated.
In general the importance of a good working relationship with the medical team can not be understated. Try to find a model that is beneficial to both partners and be open to suggestions from the medical team to improve your study.
5. Is the data of good quality?
Self learning algorithms are only as good as the data they learned from. Low quality data might have to be cleaned. Therefore you should check data quality first.
Here are 3 tips:
- Manual/visual investigation to check obvious low quality factors like missing values, anomalies, artifacts or noisiness of the signal.
- Calculating statistical properties of the input data might provide additional evidence for quality.
- Check if there is equal representation in the training and test data. For example, if you want to predict blood pressure, make sure that your training data has equal amount of data over the full range of blood pressures to avoid biasing.
After calculating statistical properties of input data and understanding what values are acceptable by visual inspection, the data cleaning process can be automated with a self-learning algorithm. If equal representation is not present, techniques like data augmentation or assigning representation weights might solve the issue.
6. Corpus size
Another question to ask yourself: “Can I get hold of enough data?” Some diseases are very rare, which is of course a good thing. A downside for the few patients that have the condition is: not enough data can be gathered to train an entire model. The dataset size is called the Corpus size.
Some workaround options exist:
- Investigate if any transfer learning can be used. This technique allows you to use data from similar datasets that are not specific to your use case. You can for example use random pictures from the web to pre-train the lower layers of your network and recognize simple things like lines and circles. Later you can fine-tune this model for your specific needs i.e. recognize specific car models. This process can be compared to first learning to see before learning to read.
- Investigate the possibility of data augmentation. In this technique the training dataset is enlarged by performing random but constrained transformations on the input data. For example providing slightly rotated and skewed pictures.
- If there is a lot of unlabeled data available this can also be used to train the data by means of pseudo-supervised learning. This technique allows to improve accuracy in supervised learning by using unlabeled data.
If these options are not within reach, you’ll have to limit your approach to Machine Learning with feature engineering (avoiding a Deep Learning approach) in which you accommodate to the amount of available data.
Depending on your answers to the previous 6 questions, you’ll know whether Machine Learning is a possible path for you. After data gathering and cleaning, the most painstaking and costly part is over. Now is the time to start implementing your algorithm.
7. Model selection
At this point there is no clear decision tree to select the right model and many heuristics exist with varying degree applicability. But fear not, there is a practical way to go about it.
The beauty of the artificial intelligence community is how open it is. Almost all major achievements are openly publicized often with code to go with them. Even giants like Google and Facebook share the algorithms they use to win competitions openly. Therefore, the first thing to do when selecting a model is looking at the inputs, desired outputs, corpus size and types of relations to be learned. Once you understand those, it is best to start looking in the scientific literature for cases that are similar. Don’t be put off by papers and their scientific notations, they underlying principles are often remarkably simple.
Don’t be constrained by the field of application either. An algorithm to detect rotten apples for a harvesting robot might well be suited to detect cancer on medical images. Or an algorithm to detect sports activities with a sports watch might help you detect Parkinson’s disease by use of a smartphone. Make abstraction of the application and focus on similarities on a system level.
The field is ever changing so don’t be afraid to look at the newest research as well as older proven technologies.
One large decision that you will have to make is the choice between the “older” feature based Machine Learning techniques or Deep Learning techniques.
A high level summary of the differences:

8. Implement your algorithm
Once you have the data and have chosen candidate Machine Learning strategies, your job is not done. Consider selecting more than one Machine Learning technique and try multiple architectures. Select an accuracy metric to score and compare the performance of the algorithms. This will help you to choose the right model and tune the system for maximized performance.
During training, engineers should keep an eye on the training process to avoid common pitfalls and to change hyperparameters during training. Hyperparameters are the settings that allow you to tweak your algorithm and guide it to good performance.
Most issues can be avoided by smart engineering:
- Avoid overfitting. Avoid using non-characteristic features in the input data to recognize or predict the input data.
- Ensure ability to generalize to practical environmental conditions: Make sure the system also works in the field.
- Apply data augmentation or other techniques to get desired results.
- Validate the algorithm on a suitable validation data set that was selected in a correct way with the good validation criteria. Cross-validation is the way to go.
- Adjust algorithm strategies if desired outcomes are not obtained.
9. Improve your algorithm
An algorithm using Deep Learning will automatically adjust features and classifiers to improve accuracy. Other forms of Machine Learning do require input from a (human) expert to verify, optimize and validate how parameters contribute to the output. It’s very likely you will have to change, remove or add parameters in your algorithm to improve prediction results.
In the end the data will guide you towards the parameters that matter and determine the requirements for a better algorithm validation dataset. The technologies and opportunities are out there. The challenge will be to implement them in a way that is both performant and compatible with your needs and the available data.
Authors: Jochem Grietens & Jan Calliauw
Download this perspective on Artificial Intelligence (AI) in valuable new (medical) solutions